本文将探讨v8是如何对utf8编码的js文件进行词法分析的!
简介
v8提供了一个Scanner类作为词法分析器,在该类中有这么一个指针:
1 | Utf16CharacterStream* stream_; |
这是个啥玩意?看一下源代码中对这个类的解释:
// Buffered stream of UTF-16 code units, using an internal UTF-16 buffer.
大概就是说,Utf16CharacterStream就是一个UTF-16代码单元的缓冲流。
啥是代码单元?v8的解释如下:
// A code unit is a 16 bit value representing either a 16 bit code point
// or one part of a surrogate pair that make a single 21 bit code point.
这就涉及到了unicode规范,在unicode字符集中,每个unicode字符都有一个唯一的代码点。
在utf8、utf16等编码形式中,代码点被映射到一个或者多个代码单元。
代码单元是各个编码形式中的最小单元,其大小:
- UTF-8 中的代码单元由 8 位组成。
- UTF-16 中的代码单元由 16 位组成。
每个代码点需要多少个代码单元呢?不同编码形式不一样:
- UTF-8中,每个代码点被映射到一个、两个、三个或者四个代码单元。
- UTF-16中,值小于等于U+FFFF的代码点被映射到单个代码单元中,对于值大于U+FFFF的代码点,每个代码点需要两个代码单元。在UTF-16 中,这些代码单元对有一个独特的术语:“Unicode 代理对”。
综上,我们可以知道Utf16CharacterStream中每一个UTF-16代码单元的含义:
UTF-16中,一个代码单元要么是一个16位的代码点,要么是“Unicode代理对”中的一半,其中“unicode代码对”是一个21位的代码点。
简而言之,Utf16CharacterStream中的每个代码单元,要么是一个独立的unicode字符,要么是一个unicode字符的一半(和下一个代码单元组合起来才能形成一个unicode字符)。
v8实际上就是基于utf16对输入字符序列进行词法分析的!这也是Ecmascript规范所要求的:
ECMAScript 源代码文本使用 Unicode 3.0 或更高版本的字符编码的字符序列来表示。
符合 ECMAScript 的实现不要求对文本执行正规化,也不要求将其表现为像执行了正规化一样。
本规范的目的是假定 ECMAScript 源代码文本都是由16位代码单元组成的序列。
像这样包含16位代码单元序列的源文本可能不是有效的 UTF-16 字符编码。
如果实际源代码文本没有用16位代码单元形式的编码,那就必须把它看作已经转换为 UTF-16 一样处理。
v8词法分析首先要做的是把输入字符序列转换成utf16 stream。
那如何把utf8编码的js文件转换成utf16 stream呢?
字节流
首先,我们需要先获得utf8字节流:
1 | // 二进制方式打开 |
假设文件内容如下:
1 | function 招聘() { |
utf8字节流如下:
1 | 66 75 6E 63 74 69 6F 6E 20 E6 8B 9B E8 81 98 28 29 20 7B 0A 20 20 20 20 76 61 72 20 E4 BF A1 E6 81 AF 20 3D 20 22 E5 A4 |
转换
现在,我们需要把utf8的字节流转换成utf16字符流,前面我们说了,词法分析器扫描的是Utf16CharacterStream类,不过这个类是一个抽象类,不能直接使用,
v8用了一个BufferedUtf16CharacterStream类来提供具体的功能,它继承至Utf16CharacterStream:
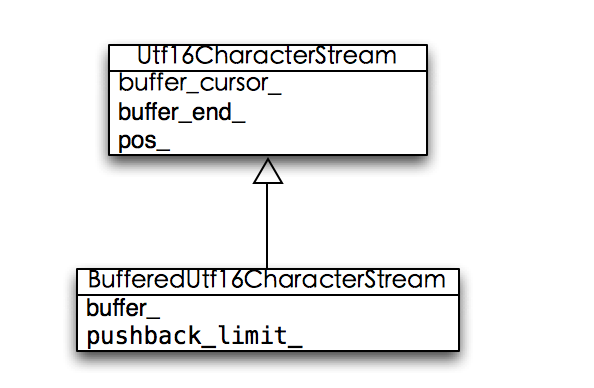
这个BufferedUtf16CharacterStream提供了一个缓冲区buffer_,我们转换的时候,就是要向这个缓冲区填充字符。
具体的转换功能由一个叫Utf8ToUtf16CharacterStream的类提供,它继承至BufferedUtf16CharacterStream:
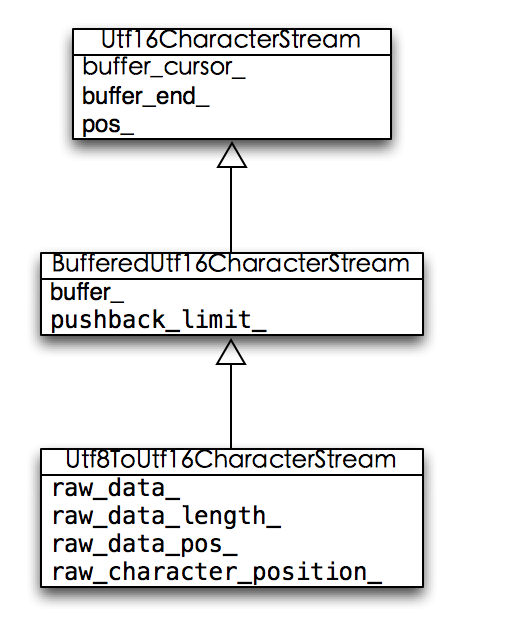
基本用法:
1 | // utf8字节流数组头部指针,指向第一个字节 |
在生成一个BufferedUtf16CharacterStream实例之时,在其构造函数中,会进行第一次字符填充。
在Utf8ToUtf16CharacterStream::FillBuffer方法中,有这么一段代码:
1 | while (i < kBufferSize - 1) { |
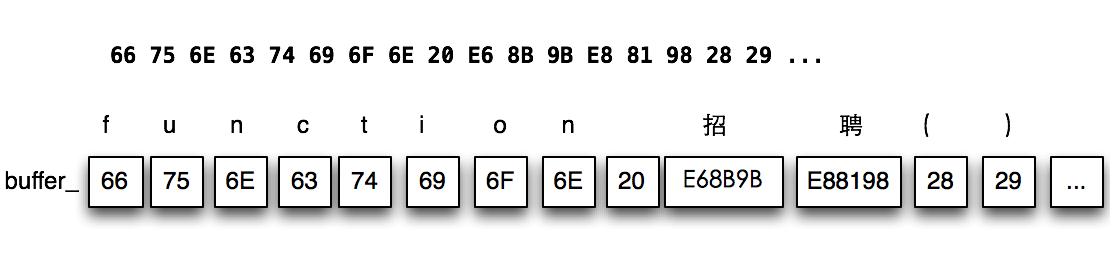
最后的结果就是,BufferedUtf16CharacterStream::buffer_中的每一个元素都是一个16位代码单元,它要么是一个字符,要么是一个“Unicode代码对”的一半。
我们以上文得到的字节流为例,最后BufferedUtf16CharacterStream::buffer_中会类似这样:
得到所有字符之后,接下来的工作就是扫描每个字符,分析出Token。
扫描
v8扫描BufferedUtf16CharacterStream::buffer_中的每个代码单元,然后按照Ecmascript的文法产生式分析出所有Token。
我们先来看看Scanner::Next这个方法:
1 | // 是否ASCII字符 |
我们注意到上面代码中的one_char_tokens,这货是啥?它其实就是个大小为128的数组,其中元素大部分是Token::ILLEGAL,只有几个有效的Token:
- Token::LPAREN “(“
- Token::RPAREN “)”
- Token::COMMA “,”
- Token::COLON “:”
- Token::SEMICOLON “;”
- Token::CONDITIONAL “?”
- Token::LBRACK “[“
- Token::RBRACK “]”
- Token::LBRACE “{“
- Token::RBRACE “}”
- Token::BIT_NOT “~”
如果没匹配到one_char_tokens,则调用Scanner::Scan继续扫描:
1 | switch(c0_) { |
注意到上面的ScanIdentifierOrKeyword方法,这个方法是Token分析的核心,顾名思义,它就是用来分析identifier或者keyword的:
1 | // 字符链 |
我们以前文的buffer_字符数组为例,经过Scanner扫描后,会产生类似这样的结果:
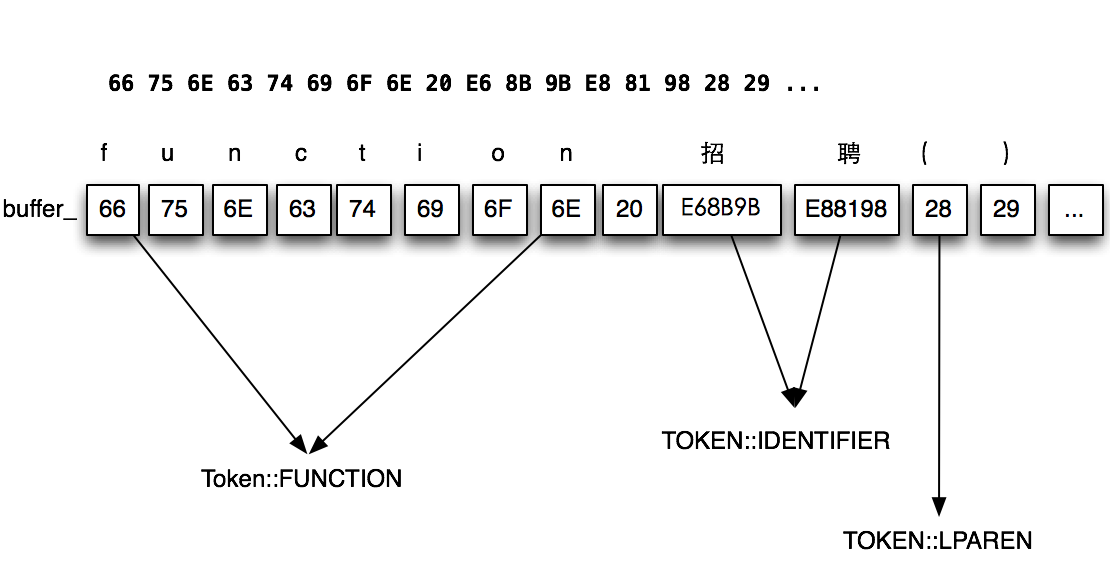
最后,对整个文件内容扫描完的结果大概就类似这样:
1 | No of tokens: 12 |
在utf8编码的情况下,v8整个词法分析过程,大概就是这样,当然实际过程中,还有很多细节问题需要处理,比如跳过js注释、html注释
、扫描十六进制字符、8进制字符、unicode转义字符等等
这就是本人粗略看了v8词法分析源码之后的一点理解,欢迎各路大神点评!
